通过主从复制功能,创建一个或者多个从库,可以有效提高数据库的可用性、可扩展性。当主库发生故障时,可以快速将某一个从库切换为主库使用而不影响正常业务;随着系统中业务访问量的增大,可以把读请求的负载分布到各个从库上,写请求则转发给主库,形成读写分离的架构,来提供更好的读扩展和请求的负载均衡。
主要用途
- 读写分离
在日常的开发过程中,某些业务操作数据库时需要锁表或锁行,这会影响进程的正常运行,使用主从复制后,让主库负责增删改,从库负责读,这样即使主库出现了锁表的场景,也不会影响业务的正常运行。 - 架构扩展
随着系统中业务访问量的激增,如果是单机部署 mysql ,就会出现性能瓶颈,有了主从复制,增加多个从库,将请求的负载分发到多个从库,可有效提升业务承载能力。 - 故障切换
因为数据是实时备份的,当主库因某种意外原因突然不可用时,将某一个从库切换为主库使用(主从切换),可以快速的完成故障切换,从而减少对业务的影响。 - 高可用(HA)
核心步骤
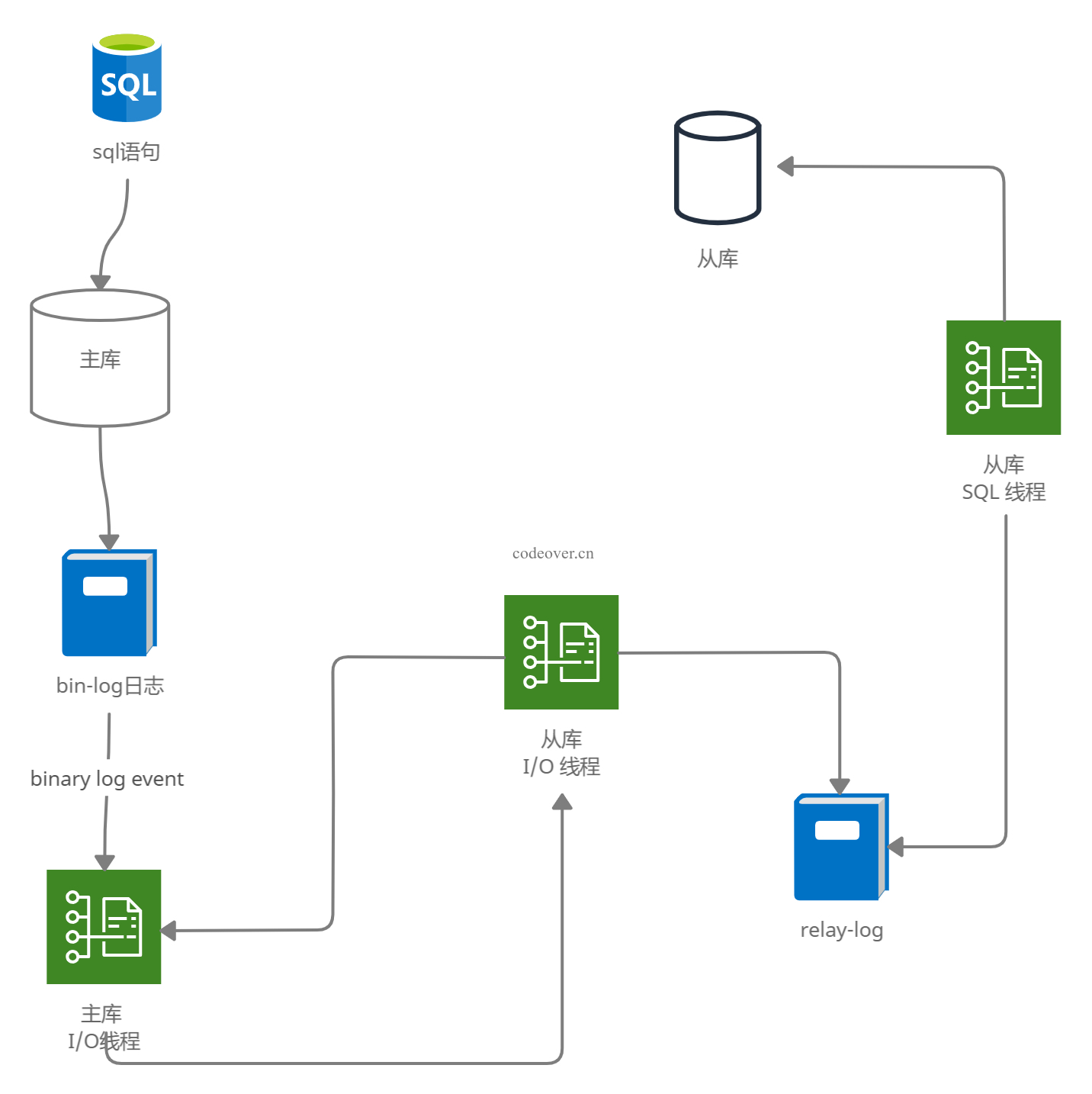
- 主节点将改变内容记录到二进制日志(mysql binlog)中,这些记录叫做二进制日志事件(binary log events)
- 从库启动 I/O线程 ,与主库建立客户端连接,并请求从指定指定日志文件(binlog)的指定位置(或从最开始的日志)之后的日志内容。
- 主库启动 binlog dump进程 ,读取主库的
binary log event并发送给从库的 I/O进程 。 - 从库的 I/O线程 获取到主库发送的日志内容(binlog)后,将收到的日志更新到本机的中继日志(relay-log)中,
- 从库的 SQL线程 检测到
relay-log新增了内容后,将relay-log中的内容解析为 SQL 语句执行。
模型
在项目在刚起步时,一般单体应用就足够了,很少会有一开始就高主从架构的,费时间、费钱而且徒增了复杂度。当业务扩展,请求膨胀,主库几乎无法承担压力了,就会开始考虑开始部署主从复制。
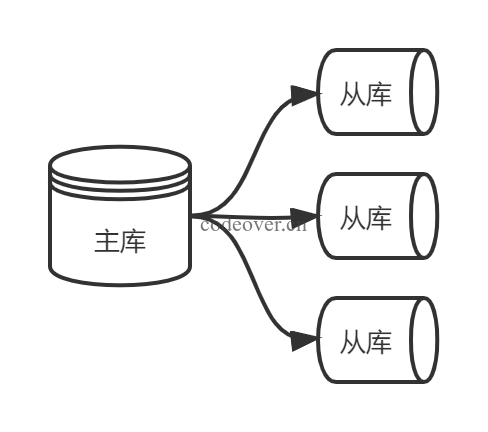
一主多从
一主一从或一主多从是最常见的主从架构,实施起来简单并且有效。一主多从模型适合少量写,大量读的业务场景,可以将读请求分发至各个从节点,可有效地减轻主库的读压力
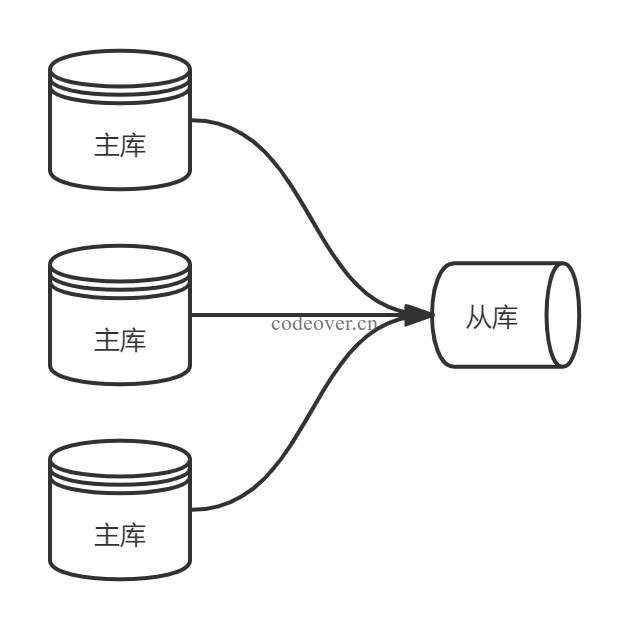
多主一从
多主一从可以将多个主库备份到同一从数上,一般情况下不会使用此模型。此模型需要 mysql 版本大于等于 5.7
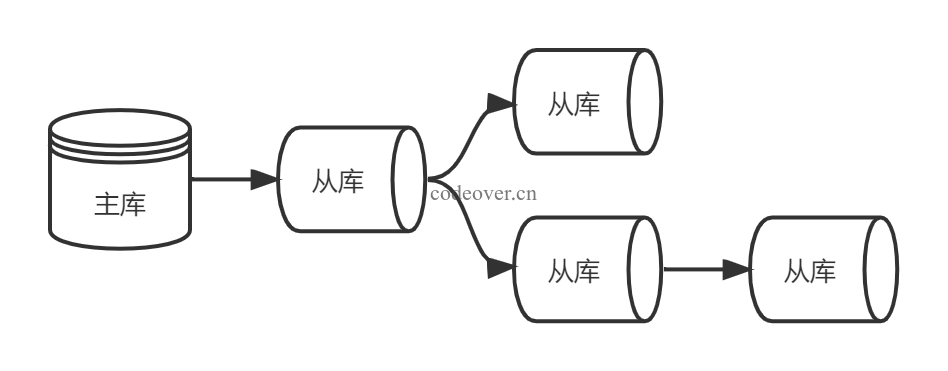
级联复制
主节点如果有太多的从节点,就会损耗相当一部分性能用于复制数据(replication),级联复制就是使部分从节点同时担任主节点的复制(replication)工作,这样不仅仅可以缓解主节点的压力,并且对数据一致性没有影响。
主主复制
主主复制就是两个主库相互复制。可以对任何一个数据库进行写操作,任何一个数据库的数据发生变化都会同步到另一台服务器上,这种模式任何一个库挂了都不会对业务造成致命影响。
但是主主复制实际上并不可靠,两个主库发生冲突的可能性是极大的,加入复制停止了,系统仍在向两个主库中写入数据,也就是会出现一部分数据在库A,一部分数据在库B,要恢复这部分数据的难度会非常大。
模式
mysql 主从复制默认是异步模式,mysql 增删改操作会全部记录在 binlog 中,当从库连接到主库时,会主动的从主库获取最新的 binlog。
异步复制
异步模式(mysql async-mode)下,主库不会主动地向从库推送,而是等待从库的 I/O线程 连接建立。主库在执行完自己的的事务之后直接将结果写入 binlog ,不会关心从库是否已接收并处理,这种模式下处理请求与主从复制是完全异步的,如果从库在执行复制时挂掉,可能会出现主从数据不一致的现象。
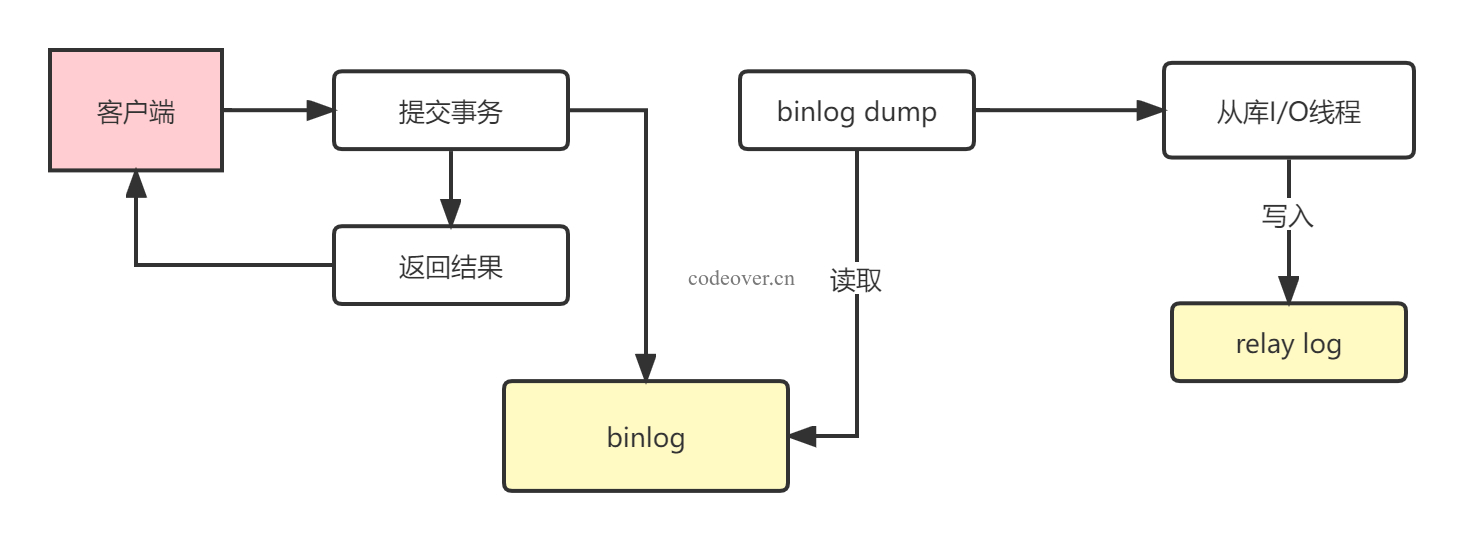
同步复制
在同步复制模式下,主库执行完一个事务,必须等待所有从库全部执行完复制,才会给客户端返回成功,也因此同步模式下,性能会大打折扣。
指的注意的是,在此模式下,主库会直接提交事务,而不是等待所有从库复制完才提交,此模式只是延迟了对客户端的返回,所以在极端情况下此模式依旧会出现主从数据不一致的情况。
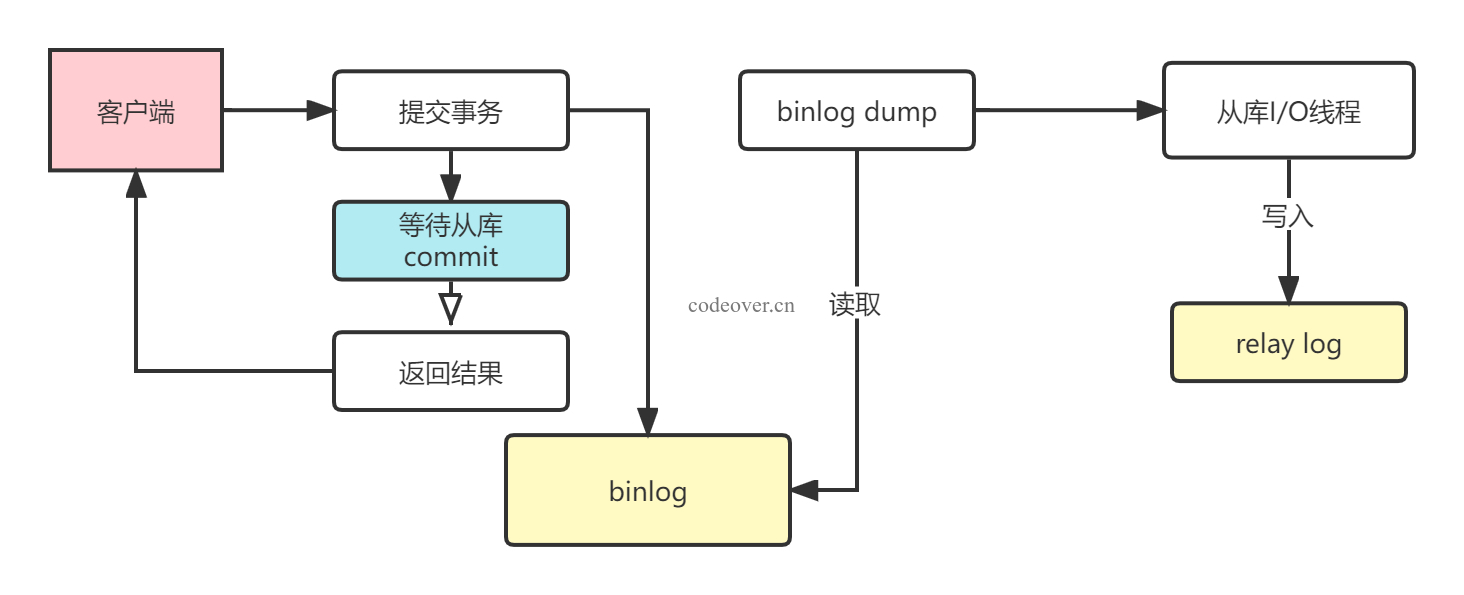
半同步模式
半同步模式(mysql semi-sync)介于异步复制与同步复制之间,与同步模式一样,在主库执行完事务后不会立即提交,而是至少一个从库收到并写入到中继日志(relay-log)后才返回成功信息给客户端(只保证记录到中继日志中,并不能保证从库能正确的将此事务更新到 DB 中),如果超过了默认的时间人没有从库写入成功,就会切换到异步模式提交。相对于异步复制,一定程度上保证了数据能准确同步到从库,同时相对于同步复制节省了部分性能。
总结
mysql 主从复制是 mysql 高可用、高性能的基础,有了这个基础,mysql 的部署会变得灵活并且具有多样性、可扩振性,从而可以根据不同的业务场景做出灵活的调整。
在实际应用中,设计之初就应根据具体需求确立复制模型与复制方式,并定期检查数据一致性,以免主库发生意外却无法及时切换从库使用。