Elasticsearch 是一个分布式的搜索和分析引擎,可以用于全文检索、结构化检索和分析,并能将这三者结合起来。Elasticsearch 基于 Lucene 开发,是 Lucene 的封装,提供了 REST API 的操作接口,开箱即用。现在是使用最广的开源搜索引擎之一,Wikipedia、Stack Overflow、GitHub 等都基于 Elasticsearch 来构建他们的搜索引擎。
安装
Elasticsearch 安装相对简单,只需安装 JDK[1]
安装 JDK
yum install java-1.8.0-openjdk # 👈 CentOs |
下载完后运行以下命令检查
java -version |
下载并安装 Elasticsearch
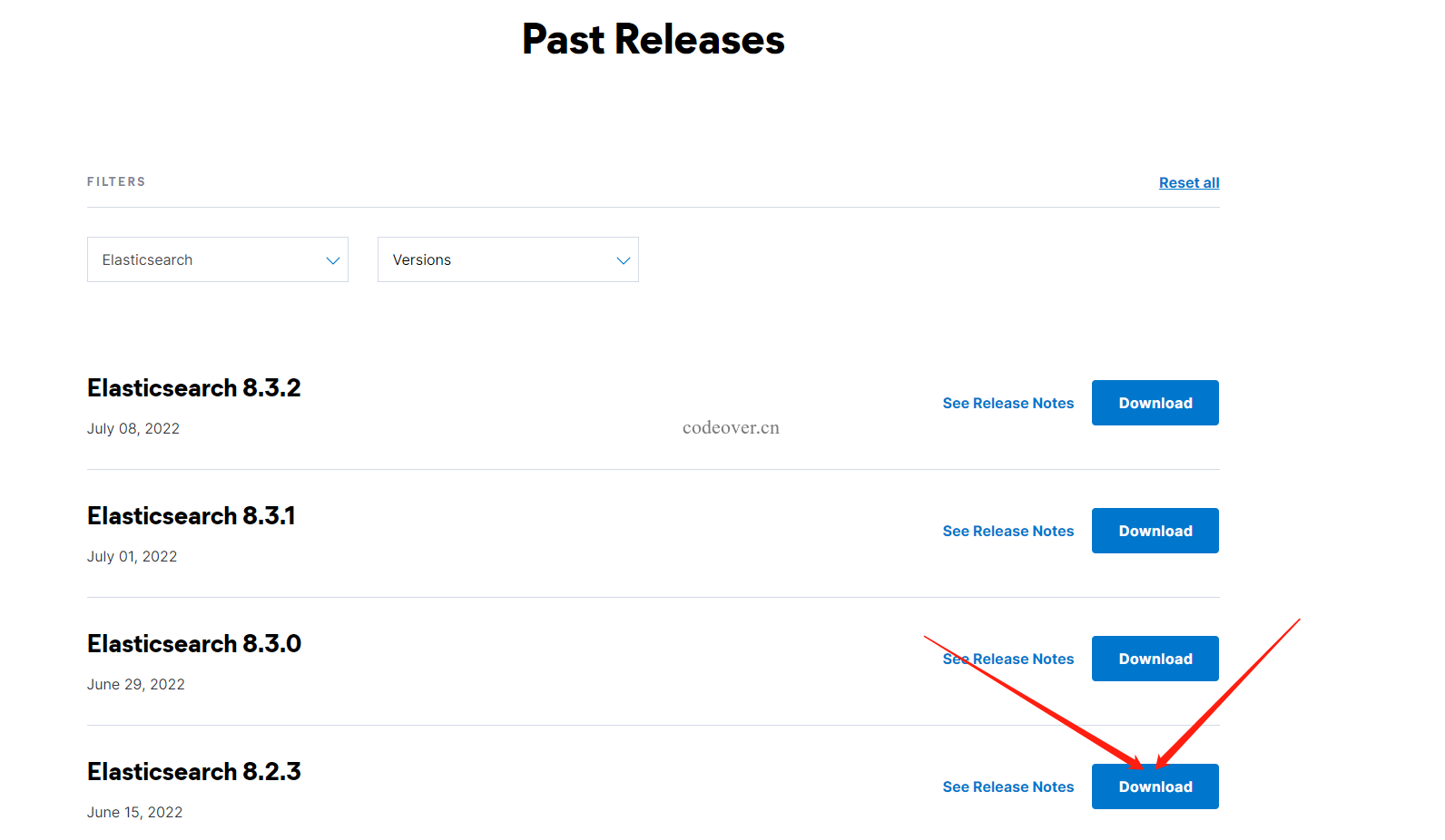
打开网址:https://www.elastic.co/cn/downloads/past-releases#elasticsearch
选择适合的版本点击 Download 按钮,本文选择安装 8.2.3 版本「截止发文 ik 插件最新版为 8.2.3」

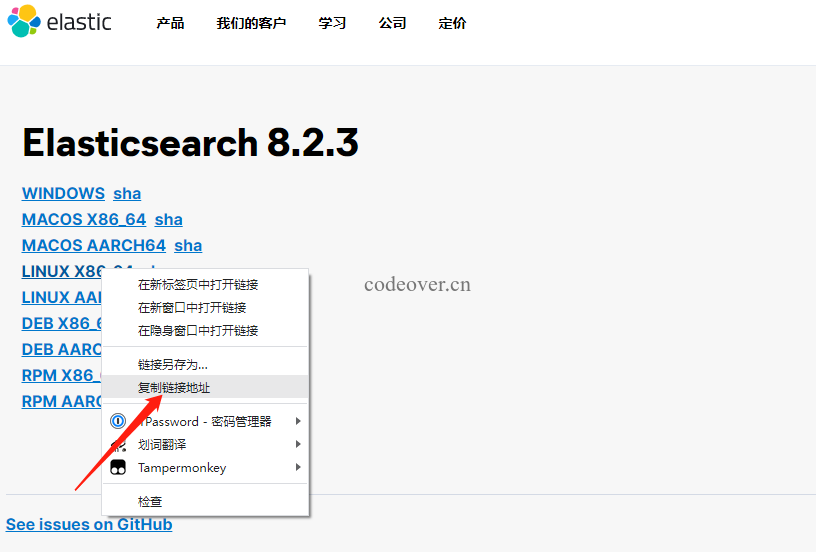
选择 LINUX X86_64 右键点击复制链接
使用
wget命令下载并解压到你喜欢的路径# 此过程在国内服务器较为缓慢
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.2.3-linux-x86_64.tar.gz -O elasticsearch.tar.gz
tar -zxvf elasticsearch.tar.gz
# 将 elasticsearch 移动到 elasticsearch 目录
mv elasticsearch /www/server/elasticsearch
运行
Elasticsearch 不可以使用 root 用户运行,所以在执行以下命令前需要切换至普通用户,并赋予该用户对应命令的执行权限
/www/server/elasticsearch/bin/elasticsearch -d |
连接测试
curl 'http://localhost:9200/?pretty' |
如果一切正常,将会返回类似如下格式内容
{ |
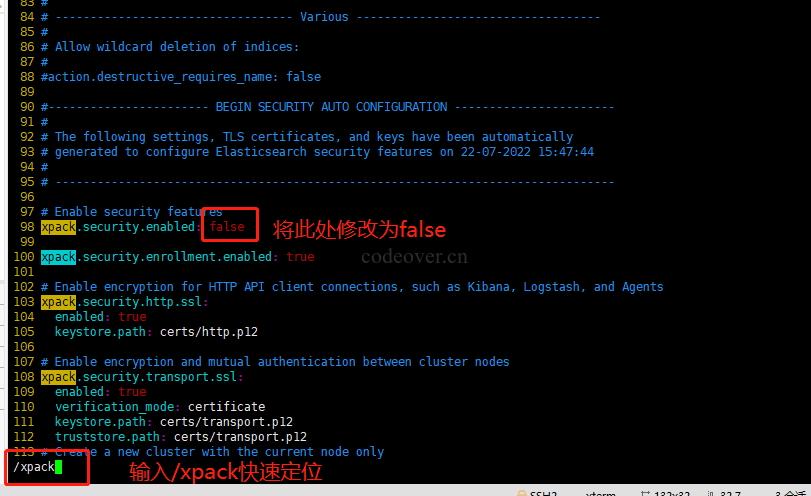
如果遇到报错,是因为 Elasticsearch 8 默认开启了 X-Pack[2]config/elasticsearch.yml 在 98 行左右将 xpack.security.enabled: false 修改为 false,如图
基础概念
Elasticsearch 是一个基于文档的 NoSQL 数据库,是一个 分布式、RESTful风格的搜索和数据分析引擎,同时也是 Elastic Stack 的核心,集中存储数据。Elasticsearch、Logstash、Kibana 经常被用作日志分析系统,俗称 ELK。
说白了就是一个数据库,既然是数据库,有一些概念是互通的,如下表:
| MySQL | Elasticsearch |
|---|---|
| 表(Table) | 索引(Index) |
| 记录(Row) | 文档(Document) |
| 字段(Column) | 字段(Fields) |
基础操作
以下为 Elasticsearch 常用的 API,其中 {index_name} 代表自定义的索引名称,{id} 为文档的 ID「Elasticsearch 的 ID 并非自增,所以需要自行指定」。Elasticsearch 的返回值是 JSON 格式,在对应地址后添加 ?pretty 即可获取格式化的 JSON 内容
| 请求方式 | 请求路径 | 说明 |
|---|---|---|
| PUT | /{index_name} | 创建索引 |
| GET | /{index_name} | 查看索引信息 |
| PUT | /{index_name}/_mapping | 修改索引字段 |
| PUT | {index_name}/_doc/{id} | 创建\编辑文档 |
| DELETE | {index_name}/_doc/{id} | 删除文档 |
| GET | {index_name}/_doc/{id} | 读取文档数据 |
| POST | {index_name}/_search | 搜素数据 |
创建索引
curl -XPUT http://localhost:9200/test_index |
查看索引信息
curl http://localhost:9200/test_index |
为索引创建类型
curl -H'Content-Type: application/json' -XPUT http://localhost:9200/test_index/_mapping -d'{ |
properties表示这个索引中各个字段的定义,其中key是字段名称,value是字段的定义type定义了字段的数据类型,常用的类型有text/integer/date/boolean/keyword,可以在 这个连接 查看所有类型analyzer告诉 Elasticsearch 使用什么方式给这个字段分词,示例中使用了ik_smart,这是一个中文分词器,后文会有介绍。
创建文档
curl -H'Content-Type: application/json' -XPUT http://localhost:9200/test_index/_doc/1 -d'{ |
URL 中的 1 是文档的 ID,这点和 Mysql 不太一样,Elasticsearch 的文档 ID 不是自增的,需要我们手动指定。
读取文档
curl http://localhost:9200/test_index/_doc/1 |
URL 中的 1 即创建文档时的ID
搜索
curl -XPOST -H'Content-Type:application/json' http://localhost:9200/test_index/_search?pretty -d' |
返回内容
{ |
ik_smart 会把『全新国产』分词成『全新』和『国产』两个词,当我们用 match 来搜索时,Elasticsearch 就会拿搜索词在分词结果中寻找完全匹配的文档。
Elasticsearch 查询
布尔查询
Elasticsearch 的布尔查询(Bool Query)与 SQL 语言中的 and / or 有些类似,可以根据多个条件来筛选文档。
布尔查询下可以有 4 类条件,每个类条件对应的项都是一个数组,数组内的每个项对应一个条件
filter与 SQL 语句中的and类似,查询的文档必须同时满足类下的所有条件。must与filter相同,区别在于must方法会参与 打分,而filter不会。should查询条件不需完全满足,默认情况下只需要满足should下的一项即可,可以通过minimum_should_match参数来改变需要满足的个数,满足的条件越多对应文档的打分就越高。must_not与must相反,查询的文档必须不符合此类下的所有条件。
示例如下:
curl -XPOST -H'Content-Type:application/json' http://localhost:9200/test_index/_search?pretty -d' |
在上面的示例中,查询条件必须同时满足 title 包含 iPhone 且 description 包含 全新
分页查询
分页是数据库查询的一项非常重要的功能,Elasticsearch 提供了 from 和 size 两个参数,其含义与 SQL 语句的 limit $offset, $count 语法中的 $offset 与 $count 参数完全一致。
示例如下:
curl -XPOST -H'Content-Type:application/json' http://localhost:9200/test_index/_search?pretty -d' |
此示例中从第 0 个文档获取,共获取 10 个文档,返回数据中心的 $results['hits']['hits'] 数组包含了此次查询符合条件的文档,$results['hits']['total']['value'] 则代表整个索引中符合查询条件的文档数量。
排序
Elasticsearch 的排序很简单,只需要一个 sort 参数,sort 参数是一个数组,数组下的项可以有多种格式,我们常用的格式是 key value 数组,key 是要排序的字段,value 可以是 desc 或者 asc。
示例
curl -XPOST -H'Content-Type:application/json' http://localhost:9200/test_index/_search?pretty -d' |
该示例使用 price 对查询结果进行排序。
多字段匹配查询
curl -XPOST -H'Content-Type:application/json' http://localhost:9200/test_index/_search?pretty -d' |
该示例同时搜索 title 与 description 字段,其中 title 字段的权重为 2
中文分词
Elasticsearch 默认提供了一堆的分词器,比如 standard、whitespace、language(比如english) 等分词器,但是都对中文分词的效果不太好,为了实现更好的搜索效果,我们需要安装第三方分词器来进行分词,比较常见的就是 ik 分词器。
ik 分词器的安装比较简单,首先前往 github 选择与你的 Elasticsearch 相同的版本下载,下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases,随后解压至 的 plugins/ik/ 目录下即可。如下下载 8.2.3 版本:
cd /www/server/elasticsearch/plugins |
分面搜索
我们可以在京东上搜索一下『手机』:
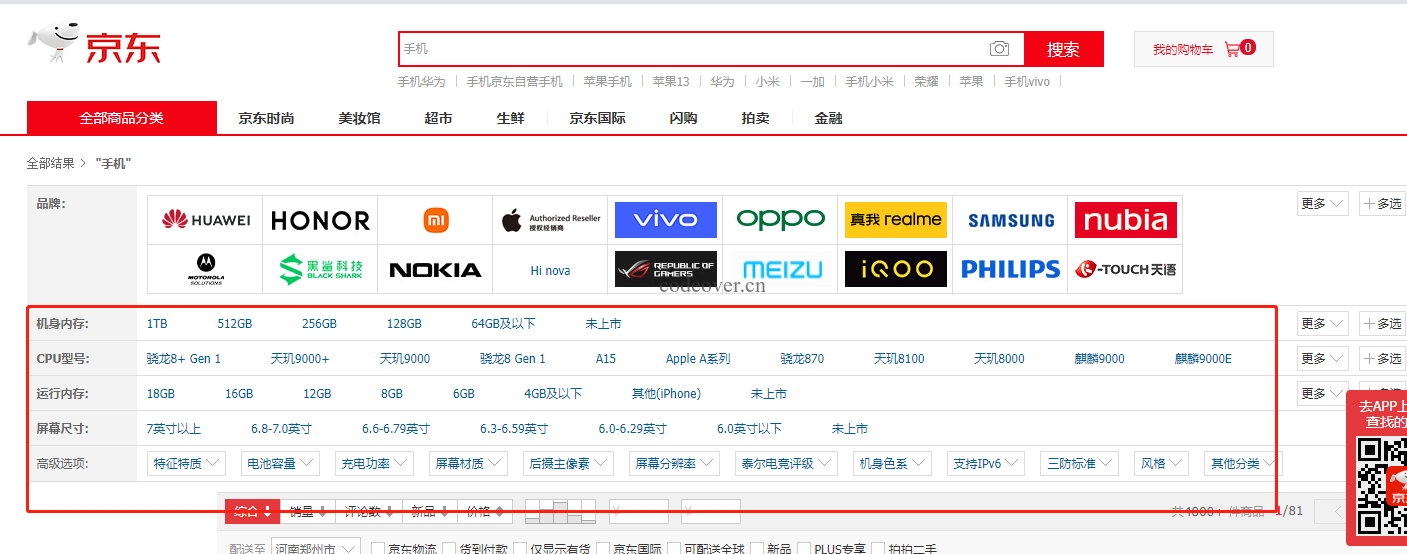
我们可以看到京东把一些属性聚合在一起并做成了链接,我们可以点击聚合的链接进一步的筛选商品,这个功能就叫做分面搜索,分面搜索是搜索引擎中非常重要的一个功能,可以帮助用户更方便的搜索想要的商品。
想要实现分面搜索就需要用到 Elasticsearch 中的聚合,其与 SQL 语句的 group by 有些类似,但更加灵活和强大
在实现分面搜索之前,我们需要先对索引结构进行调整:
curl -H'Content-Type: application/json' -XPUT http://localhost:9200/test_index/_mapping -d'{ |
可以看到我们在 test_index 索引新增了一个 properties 字段用于储存商品属性,并插入了三条测试文档。接下来我们尝试进行搜索:
curl -XPOST -H'Content-Type:application/json' http://localhost:9200/test_index/_search?pretty -d' |
以上搜索条件返回如下:
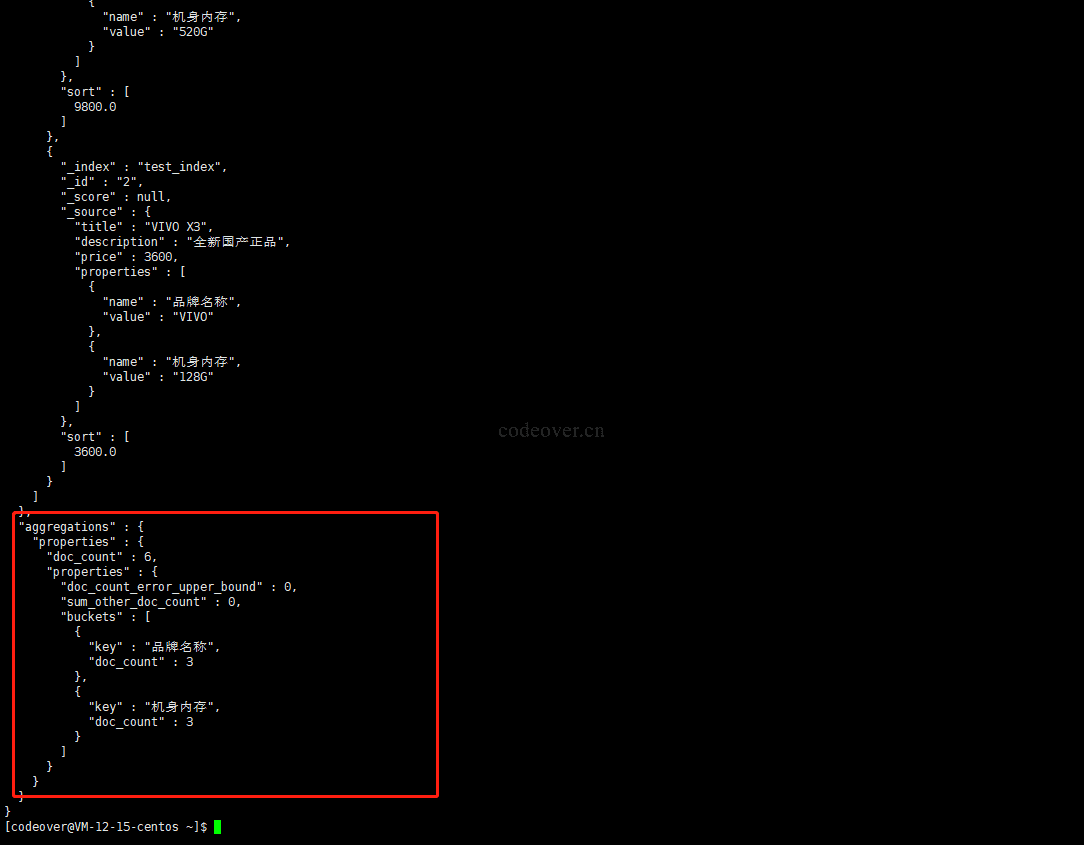
以下为对应字段解释
'aggs' => [ |
返回信息解释:
// 聚合结果 |
解决下我们进行第三层聚合,也就是属性值的聚合
curl -XPOST -H'Content-Type:application/json' http://localhost:9200/test_index/_search?pretty -d' |
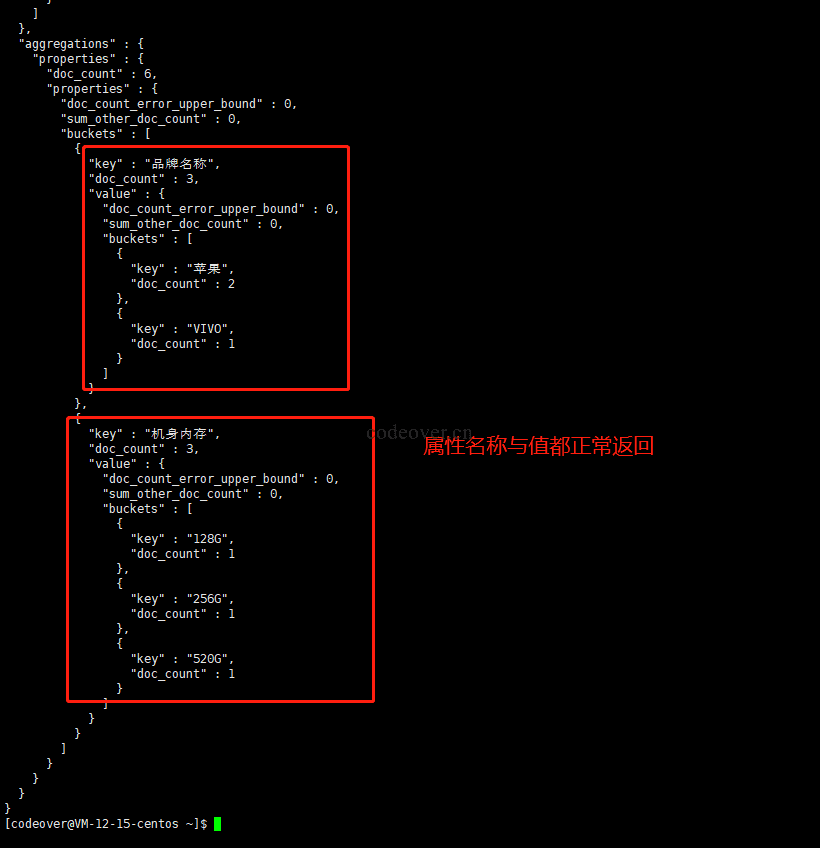
此时可以看到几乎已实现类似于京东分面搜索的功能。
同义词搜索
在前面的内容中,我们实现了基本的搜索,某个文档要想在某个关键词搜索结果中出现,就必须在文档内容中出现该关键词,这样就需要给商品配置巨量的关键词才能让商品出现的频率提高, 对运营管理人员不甚友好。为了解决这个问题,我们就需要让搜索引擎支持 同义词搜索,比如用户搜索「苹果手机」,那么包含 「Iphone」 的文档也会出现在搜索结果中。
作为目前最强大的搜索引擎之一,Elasticsearch 是默认支持 同义词搜索 的。
分析器
Elasticsearch 的分析器是由 「字符过滤器」、「分词器」与「字符过滤器」三部分组成,Elasticsearch 内置了一些 「分析器」,同时也允许我们自行定义分析器。
- 字符过滤器:「字符过滤器」会以字符为单位,根据一定的规则去添加、删除、替换原始字符串,比如将汉字的 「一二三四」替换成阿拉伯数字「1234」,一个「分析器」可以包含 0 个或多个「字符过滤器」。
- 分词器:「分词器」是根据一定的规则,将原始字符串拆分成一组组的词语,比如前文介绍的
ik_smart分词器,其可以将「苹果手机」拆分成「苹果」和「手机」两个词语,一个「分析器」有且仅能有一个「分词器」。 - 词语过滤器:「词语过滤器」会根据「分词器」的分词结果,以词语为单位,根据一定的规则去添加、删除、替换词句,例如同义词过滤器
synonym可以将「西红柿」替换为 「西红柿」+「番茄」两个词,一个「分析器」可以包含 0 个或多个「词语过滤器」。
自定义分析器
首先我们先创建同义词对应关系的文本文件,格式形如 iPhone,苹果手机 => iPhone,苹果手机,每行一组关键词:
cd /www/server/elasticsearch/config/ |
接下来我们创建一个自定义分析器,我们创建一个新的索引来测试,Elasticsearch 支持在创建索引的同时创建「分析器」:
curl -XPUT -H'Content-Type: application/json' http://localhost:9200/test_synonym?pretty -d' |
在这个请求中我们在 analysis 下的 filter 中定义了一个名为 synonym_filter 的『同义词词语过滤器』,并且指定同义词的字典路径为 analysis/synonyms.txt;同时在 analyzer 下定义了一个名为 ik_smart_synonym 的「自定义分析器」,并指定 ik_smart 作为「分词器」,上面定义的 synonym_filter 作为「词语过滤器」。
测试
我们来测试一下这个分析器的效果:
curl -H'Content-Type: application/json' http://localhost:9200/test_synonym/_analyze?pretty -d '{"text": "苹果手机","analyzer":"ik_smart_synonym"}' |
返回内容如下:
{ |
可以看到「分析器」将关键词 苹果手机 拆分成为了 iphone 、 苹果 与 手机 三个词。
在 php 中使用 Elasticsearch
- 引入 Composer 包
Elasticsearch 官方提供了 Composer 包,因为不同版本的 Elasticsearch 的 API 略有不同,所以在引入时需要注意要指定版本,例如引入 8.x 版本:
composer require elasticsearch/elasticsearch '^7.0' |
- 实例化 Elasticsearch 实例
$builder = Elastic\Elasticsearch\ClientBuilder::create()->setHosts(['localhost:9200']); |
SDK 详细使用说明可参考官方文档:https://www.elastic.co/guide/cn/elasticsearch/php/current/_quickstart.html